- Blog/
Hardware Exploits - An Overview
Table of Contents
Overview #
Hardware exploits are a lucrative target for threat actors. Once an exploit is found, it is difficult, expensive and slow to patch it, sometimes impossible for some exploits. This means that exploits can exist for a long time on some systems whose owners may not possess the resources necessary to patch them. On top of that, these exploits are a lot more universal. Some exploits may only require a certain hardware generation to be installed in the victim (e.g. some CPU architecture or DRAM generation), whereas software exploits often require specific, unpatched, software versions to be accessible for exploits to be successful.
Cloud vendors likely are the group most affected by hardware exploits. After all, the easiest way to be able to run untrusted code on a remote machine is to just rent one. Hardware exploits do not require special privileges, relying on side effects of the hardware during “normal” operation to break systems. Patching these exploits can become extremely expensive for large cloud providers, whose entire infrastructure may be vulnerable.
A running exploit is very difficult to detect before it’s too late. Most exploits rely on microarchitectural behaviour that is undetectable from an outside perspective. Additionally, the characteristics of running exploits can easily be misclassified. Andrew Cooper, from the Xen security team, recalled at a talk about how Microsoft Azure tried to use machine learning to identify exploits using transitive execution running on their cloud infrastructure. However, they were more successful in finding running Postgres databases under heavy loads, rather than actual exploits.
CPU Exploits #
Cache Timing Attacks #
Cache timing attacks cover a wide range of attacks which rely on timing memory accesses to determine whether a value is in the cache or not.
Such attacks are potent against badly designed cryptography libraries, but with some creativity, they can become a threat in many areas. Previous research has shown it possible to derandomize ASLR by relying on timing MMU page table walks to uncover addresses, even in sandboxed environments. Other methods have been presented which allow tracking of user behaviour through untrusted webpages.
byte T_Table[128] = { ... };
byte sign_msg(byte msg, byte key) {
if (key == 0) {
return msg ^ T_Table[0];
}
return msg ^ T_Table[64];
}
An example crypto function that could be exploited.
If the key is 0, then the attacker can observe a cache hit on T_Table[0].
Else, the entry T_Table[64] is hot.
The general way cache timing attacks work is by first removing a certain memory location from the cache by some means.
This can be achieved using a clflush instruction or by evicting the data entry, the latter of which being a bit more involved of a method.
The attacker then performs some operation like calling a library function, inducing an address translation, etc.
In the last step, the attacker times the access to the memory location again.
If the memory access is quick, the attacker can deduce that a cache hit occurred, meaning the victim must have accessed the memory location.
If the access takes long, however, the attacker knows that no access to the memory location has been performed by the victim.
Another way of performing a cache timing attack that doesn’t just measure one memory location at a time is by using the PRIME+PROBE method. In this method, an attacker allocates a chunk of memory which covers one full cache set. For simplicity’s sake, let’s assume that the attacker has an array of memory pointers, where the pointers together cover a cache set. This means that the length of the array is equal to the wayness of the cache and that every element in this array points to the same cache set. If the elements in the array are now accessed sequentially, this means that the targeted cache set is now populated with exactly these memory locations. Accessing these elements again will now always lead to a cache hit. The attacker can then measure the access times to the elements again at a later point, be this after some time passed or after the attacker triggered a certain action. This access time can now give the attacker an understanding of memory accesses made by the victim, which can for example be used to profile users in browsers through a malicious ad.
Mitigations to such attacks may include using constant-time algorithms such that memory accesses are always deterministic and don’t change with different parameters, such as keys or other secrets. Defenders have also tried to mitigate such timing attacks in browsers by worsening their timers, making them more inaccurate. The intent behind this was to make it impossible to differentiate between cache hits and cache misses. This method has flaws, however, as artificial noise can be eliminated through repeated measurements, and making the timers too inaccurate could interfere with legitimate applications. Additionally, researchers were able to create timers through other means which circumvent this mitigation.
Transient Execution Vulnerabilities #
To improve performance, modern CPUs use speculative execution. This allows CPUs to run instructions out of order, thereby making stalls (e.g. from a slow memory access) less impactful.
With transient execution, CPUs commit or rollback instructions when they are completed or have become invalid (for example if a branch was mispredicted). However, when rolling back instructions, the microarchitectural state, which includes caches and certain buffers, does not get reverted. These microarchitectural remains provide attackers with a side channel for extracting information.

Meltdown #
Meltdown was the first hardware attack exploiting transient execution in CPUs.
byte *kernel_ptr = ... ;
byte arr[256 * 64];
arr[*kernel_ptr * 64];
A toy example of the meltdown attack.
If the value at *kernel_ptr is x, then the entry arr[x * 64] will be hot.
It is very simple in its functionality. In some CPUs, when the CPU has to access a memory location, it performs the access and permission checks in parallel, leading to a race condition. This means that it is possible to induce an illegal memory access and perform operations on the acquired value before the CPU raises an exception. Attackers can use this behaviour to prime other memory locations which they can later time to differentiate between a cache hit or miss.
The only detail attackers must consider is how to suppress the induced segfault due to the illegal memory access. This is easily done by registering a signal handler or using other methods, such as Intel TSX.
Only some CPUs were affected by this vulnerability, as not all perform the permission check in parallel with the memory access. Meltdown primarily affected Intel x86 CPUs, but the ARM Cortex-A75 and IBM’s Power microprocessor were also vulnerable.
With the vulnerability being disclosed, many mitigations were implemented by Linux kernel developers, Microsoft, Apple and more.
In the Linux kernel for example, developers implemented kernel page-table isolation (KPTI), which hardens the kernel by better isolating user space and kernel space memory.
Newer Intel CPUs are no longer affected by this vulnerability, with Intel including hardware patches.
They also released microcode updates for some older CPUs which mitigate the Meltdown vulnerability.

Spectre #
Spectre describes a family of transient execution attacks which rely on mispredictions by the branch predictor in CPUs.
A branch predictor takes into account the history of conditional branches, indirect branches and return addresses pushed on the stack by call instructions.
Using these histories, branch predictors then predict where an execution will continue, given a branch.
If the branch was correctly predicted, this leads to a gain in performance.
If it was mispredicted, however, the transiently executed instructions must be rolled back and execution continues from the correct program counter.
But again, this rollback does not affect the microarchitectural state, leaving exposed a side channel.
v1 (Bounds Check Bypass) #
This is the first variant of Spectre presented in the spectre paper and exploits the branch prediction of conditional jumps.
if (x < array1_size)
y = array2[array1[x] * 4096];
Spectre v1 example.
Its functionality can be generalized but in its most intuitive form, the exploit involves an array whose bounds are checked in a loop. If the array is sufficient in size, this trains the branch predictor to always predict that the bounds check succeeds, leading the program to enter the if-block. Then, on the iteration the bounds check fails, the attacker would access the target memory location within the if-statement.
Since the branch predictor always predicts that the branch will be taken, it will transiently execute the malicious memory access. This influences the microarchitectural state while not causing any exceptions in the program, as the bounds check fails in the concrete.
Getting a signal from this attack is a bit more involved when compared to Meltdown. Here, the attacker has to intelligently induce stalls at the right points of the program, such as to ensure the malicious memory access will take place. If, for example, the conditional evaluation is too quick, the CPU will rollback the transiently executed instruction after resolving the branch before the malicious memory access can complete.
A simple mitigation for this vulnerability is to disable the speculative execution or to synchronize all loads in the pipeline.
This does of course come with a certain performance impact.
Another way to mitigate Spectre v1 is through pointer masking, where pointers are ANDed with a mask that results in a pointer that cannot point to memory the process shouldn’t have access to.
For example, if kernel memory is organized such that the first x bits are set, then the pointers are sanitized with a mask where the first x bits are unset, resulting in these pointers never pointing to kernel memory.
v2 (Branch Target Injection) #
This version was also described in the original paper and targets mispredictions of indirect branches.
Indirect branches take the address to jump to from a register and can be of the form jmp %rax or jmp (%rax).
The latter of these two may require a main memory access, which can provide attackers with a long, exploitable misprediction window.
In Spectre v2, an attacker trains the predictor to predict a jump to some code in another context by repeatedly jumping to the same address in their own context, thereby filling the branch target buffer. On context switches, the branch target buffer does not get flushed. This means that if an indirect branch at the same location in a different context gets encountered, the CPU will transiently jump to the attacker-trained location. If the transient jump location holds a disclosure gadget, the attacker can use it to leak data.
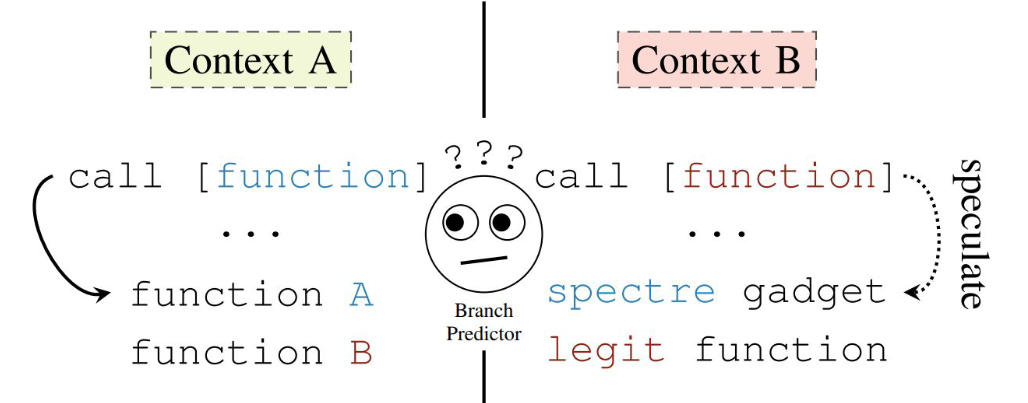
addq (%rax), %rbx;
movq (%rbx), %rbx;
A sample Spectre v2 gadget.
rax and rbx would be attacker-controlled.
A simple gadget can require only two (not necessarily adjacent) instructions.
The first instruction would be an arithmetic or bitwise instruction combining the value pointed to by the attacker-controlled register R1 with the value of another attacker-controlled register R2.
A succeeding instruction would then load the memory address in R2.
In this scenario, the attacker has control over which address to leak through R1.
R2 controls how the leaked data gets mapped to memory which the attacker can then probe for cache hits or misses.
Spectre v2, while a bit more involved and difficult to get functioning, is a lot more powerful than the Bounds Check Bypass version. With Branch Target Injection, attackers can transiently execute arbitrary code in other contexts. This gives attackers a lot more freedom in finding spectre gadgets for leaking data.
A possible way to mitigate this vulnerability is, as in Spectre v1, to add pointer masking to untrusted input or by using so-called retpolines (a combination of the words return and trampoline). Retpolines are a way of turning indirect branches into returns through simple assembly rewriting, thereby bypassing the branch predictor (which isn’t sufficient, however, as later shown by Retbleed). Additionally, Intel released microcode updates with instructions to partially flush the buffer in the branch predictor responsible for keeping track of indirect branches.
Retbleed - Return Stack Buffer (RSB) Poisoning #
RSB poisoning was not mentioned in the original Spectre paper but was rather shown to be a possibility around half a year later in a paper titled Spectre Returns!. Ultimately, Retbleed was able to realize the exploit in 2022, proving that this was indeed a vulnerability.
This method again targets part of the branch predictor, this time the return stack buffer (RSB). The RSB keeps track of return addresses and thus induces speculative execution when encountering return instructions. With the stack being kept in memory, this can lead to a large misprediction window if the return address is uncached. Retbleed thereby circumvents Spectre v2’s mitigation of the retpolines which relied on return instructions being invulnerable to speculative execution attacks.
To poison the RSB, exploiters create deep, recursive call stacks. This overflows the RSB and essentially flushes all previous entries due to the RSB’s limited size. When the recursive call stack returns, the return address of the function that originally called the recursive function will then be mispredicted to still be within the recursive function.

B:4 when A returns, leading to a wrong x being used in the transitive execution.Wikner et al., “Spring: Spectre Returning in the Browser with Speculative Load Queuing and Deep Stacks“In the above figure, A initiates the deep recursive call stack of B (recursively called at B:4), leading the RSB to be filled with the return address B:5.
Later, B’s recursion finishes and control continues at A.
When A then returns, the branch predictor mispredicts a return address of B:5, leading to transient execution with x being equal to A’s returned leak_off.
This then leads B to transitively leak the memory addressed by leak_off.
Intel’s simple mitigation to retbleed was to selectively use IBRS, which enables the processor to ignore BTB entries created from lower-privileged software. AMD proposed mitigation was jmp2ret, which replaces returns in the kernel with direct jumps to a return thunk on function returns. This mitigation leads to the kernel only having a single return, which then untrains the BTB to some degree. Another mitigation is to simply stuff the RSB with useless return addresses on context switches. However, these mitigations come at a performance cost, leading to a performance hit of 6%-39%.
RAM Exploits #
DRAM Organization Refresher #
To fully understand how and why some exploits work, it is important to understand the basics of memory architecture, as well as how systems fetch memory from RAM.
Layout #
RAM is partitioned into the following manner, in descending order of granularity:
- Channel
These are a way for systems to parallelize memory accesses. Most consumer motherboards have two channels, meaning that the CPU can fetch memory from two different DIMMs concurrently. - DIMM
These are the physical RAM sticks themselves. - Rank
DIMMs are either single or dual-rank. The rank describes how many sides of the DIMM (i.e. front and back) hold data. - Bank
Each bank has a row buffer. These row buffers hold data from the underlying activated row within the bank (i.e. the one being modified). When reading data from RAM, the bits get read from these row buffers. - Row
Memory banks contain many rows. Physically, the rows within a bank are closely stacked atop one another. - Column
Finally, rows are split up into 8 columns. Each column contains a single capacitor, which holds a single bit of data.
Dynamic RAM #
DRAM holds data by keeping capacitors charged or discharged. These capacitors are not static, i.e. they leak charge, meaning DRAM has to continuously be refreshed so as not to lose the stored data. The rate of this leakage depends on factors such as temperature or load.
With memory cell’s capacitors being so tiny, the charge they hold is equally as small. This means that the difference in charge between the DIMM reporting a 0 or 1 for a given memory cell is just as minuscule.
Fetching Memory #
A single memory request to DRAM returns eight bits, one bit from each of the eight banks of a given channel, DIMM and rank.
To fetch this data, the memory controller sends an ACTIVATE command to the DRAM. This activate command then opens the selected row in the selected bank.
Since the memory cells themselves hold a very low charge, DIMMs use sense amplifiers to amplify this signal. This signal is then stored in a row buffer, of which every bank has exactly one. The process of retrieving data from RAM’s memory cells is destructive, meaning that the data from the row that has been accessed is no longer in the row itself after the ACTIVATE command, but rather in the row buffer. When the row buffer gets closed, the DIMM has to write the data stored in the row buffer back into the original row.
What the row buffer allows is repeated memory accesses to the same row in RAM without the need to issue another ACTIVATE command.
Row buffers are closed immediately after an access if the memory controller holds a closed-row policy. If this policy is not enforced, however, the row buffer can be closed by accessing a different row in the same bank. This causes the memory controller to first send a PRECHARGE command, which writes the row buffer back into the row, before sending another ACTIVATE command to retrieve the data from a different row in the same bank.
Rowhammer #
Rowhammer is an exploit which induces bitflips on RAM DIMMs, thereby violating data integrity.
This is achieved by repeatedly accessing rows in RAM banks. Due to electromagnetic interference, this may lead to DRAM cells in rows adjacent to the ones being accessed discharging or building up a charge to the point of the system reporting a different value than what was originally stored.
Many papers have been written on this exploit, showing how it affects a wide range of DRAM DIMMs, including ones used in Mobile Phones and even ECC RAM, often used by cloud providers or in data centres.
The attack method is remarkably simple.
In its simplest form, it just requires an attacker to repeatedly access a row in a RAM bank, ensuring that all accesses reach the RAM by flushing the cache.
If the memory controller keeps a closed-row policy (i.e. it always closes the row buffer after opening it), this already leads to repeated ACTIVATE instructions, creating interference with neighbouring rows, thereby causing bitflips.
However, if the memory controller does not close the row, the attacker has to evict the row buffer by accessing a different row in the same bank, thereby issuing a PRECHARGE command.
Rowhammer can be used for corrupting a system by flipping random bits, but the bitflips can also be induced in a more targeted manner. This may allow adversaries to root Android phones or perform privilege escalations.
Many mitigations have been employed, none with full success so far.
Though there are
proven ways of (for the near future) fully mitigating rowhammer, they have not yet been incorporated by big manufacturers.
Most mitigations range from reducing memory speeds, over decreasing refresh intervals to disabling the clflush instruction, used for making sure memory accesses hit RAM and not the cache.
A prominent mitigation is Target Row Refresh (TRR) which uses hardware counters to track accesses to rows.
Later, these counters get used to refresh rows neighbouring ones suspected of being hammered.
TRR mitigates unsophisticated Rowhammer attacks, but it is trivial to circumvent by just using more aggressors to overflow the counters, as shown by
TRRespass.
Blacksmith #
Blacksmith was able to break 100% of DDR4 DIMMs, causing bitflips on all of them by fuzzing Rowhammer patterns in a frequency domain. This means that different aggressors get accessed different amounts of times (amplitude), at different intervals (frequency) and different offsets from the refresh interval (phase).
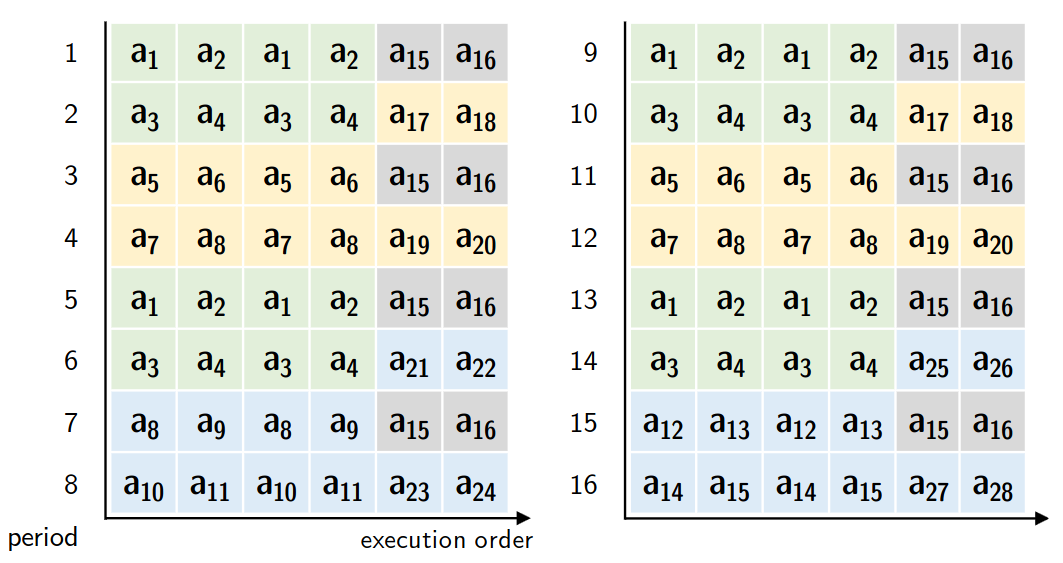
Such an approach to pattern generation hammers many aggressors, circumventing TRR in a way similar to TRRespass. However, the non-uniform amount of accesses to different aggressors also breaks other mitigations which assume that rowhammer attacks access aggressors a similar amount of times. Lastly, Blacksmith, through its phase shifts, may create patterns which exhibit the behaviour of feinting (read more about what feinting is in the ProTRR paper). In feinting, aggressors are accessed close before a refresh happens, throwing off mitigations only considering aggressor accesses within a refresh interval.
Overall, Blacksmith was able to induce bitflips on every single one of the 40 DDR4 DIMMs they tested. The least vulnerable DIMM experienced 2 bitflips within 12 hours of random hammering pattern generation, while the most vulnerable one suffered a total of 106,815 bitflips in the same time frame.
This concludes my post about these well-known hardware exploits. I hope you learned something new! :)
Thank you so much for reading through my whole post ❤️